李云龙二次元风格化!一键star、fork,你也可以生成这样的团长!
打滚卖萌求star求fork!
0.效果展示
- 视频效果前往B站观看效果最佳:李云龙二次元风格化:
- github开源repo:李云龙二次元风格化
- 百度AIstudio开源地址,一键fork即可运行: 李云龙二次元风格化!一键fork你也能行
具体详细操作也在AIstudio上一步步列举了,求star求fork! - csdn步骤解析: 李云龙二次元风格化!一键fork你也能行
1.模型简介
1.1AnimeGANv2
本文使用了animeGANv2进行了视频的风格迁移。
animeGANv2,顾名思义,是其前作AnimeGAN的改进版,改进方向主要在以下4点:
- 解决了生成的图像中的高频伪影问题。
- 它易于训练,并能直接达到论文所述的效果。
- 进一步减少生成器网络的参数数量。(现在生成器大小 8.17Mb)
- 尽可能多地使用来自BD电影的新的高质量的风格数据。
效果图参考:
本文则是使用了paddlepaddle预训练好的animeGANv2模型对李云龙名场面视频进行了风格化迁移,详情请看下文分解。

2.实现思路
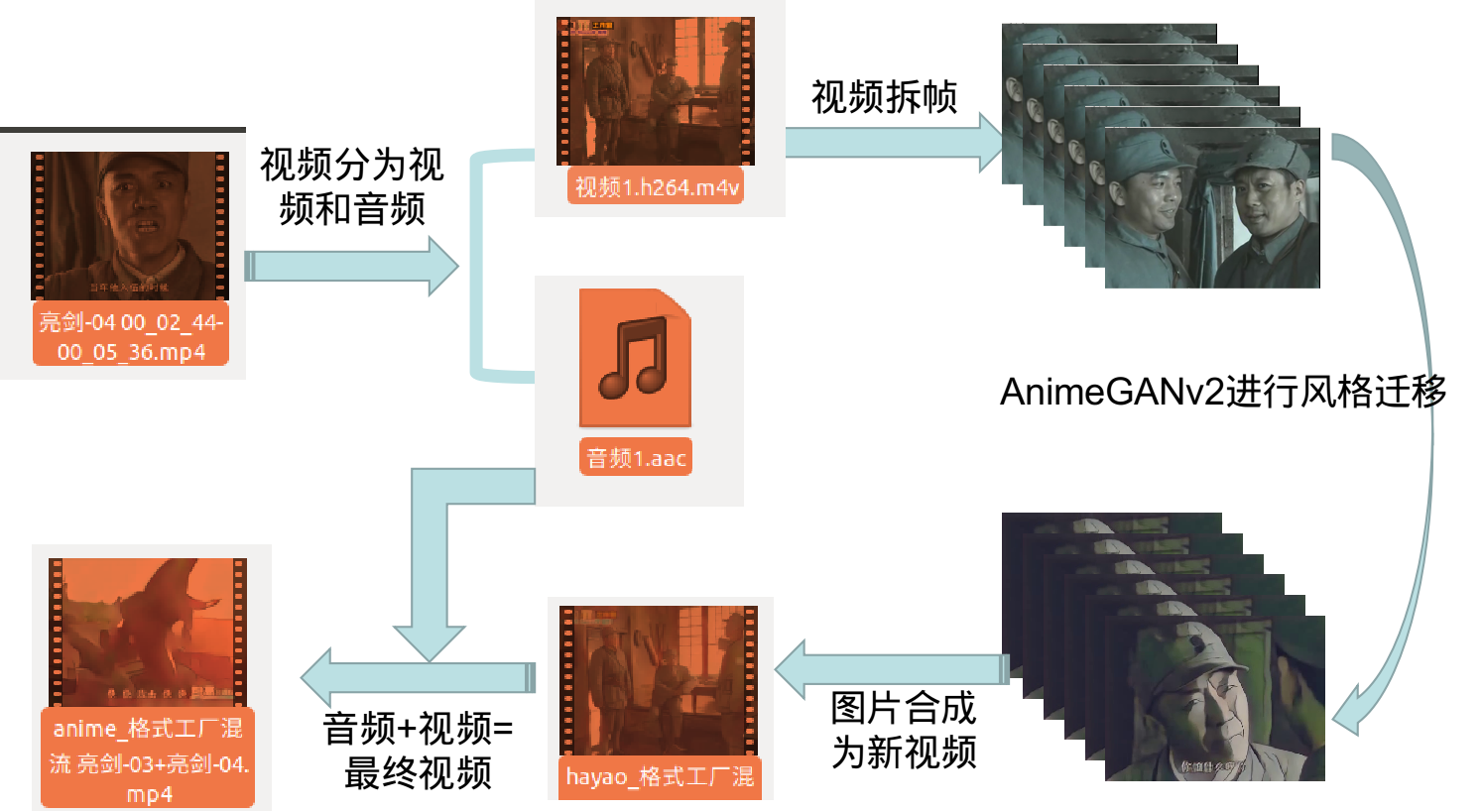
3.素材准备
首先要找到自己要操作的视频素材,将视频的音频单独提取出来备用
我自己找的资源放在了codes/videos/liyunlong文件夹下,是李云龙名场面:
你咋不敢跟旅长干一架呢!→旅长我给你跪下了 
4.代码实操:
话不多说,首先是环境的基本配置
- 安装基本环境
!pip install -r codes/PaddleGAN-develop/requirements.txt
- 导入基本环境
import paddle
import os
import sys
sys.path.insert(0,'codes/PaddleGAN-develop')
from ppgan.apps import AnimeGANPredictor
5.GAN它!
友情提示:此处最好使用GPU环境,cpu推理属实是有点点慢
进行模型的推理:
使用paddlepaddle预训练好的animeGANv2模型对视频进行风格迁移:
from ppgan.apps import AnimeGANPredictor
import cv2
predictor = AnimeGANPredictor('',None,)
video_src = 'codes/videos/liyunlong/格式工厂混流 亮剑-03+亮剑-03+亮剑-04 00_00_23-.mp4'
video_ = cv2.VideoCapture(video_src)
video_name_ = os.path.basename(video_src)
total_frames = video_.get(cv2.CAP_PROP_FRAME_COUNT)
fps_ = video_.get(cv2.CAP_PROP_FPS)
print("video {}, fps:{}, total frames:{}...".format(video_name_, fps_, total_frames))
frame_count_ = 0
save_per_frames = 1
dst_dir = 'codes/videos/liyunlong/'
out_video = cv2.VideoWriter('{}/hayao_{}'.format(dst_dir, video_name_),
cv2.VideoWriter_fourcc(*'DIVX'), int(fps_),
(int(video_.get(3)), int(video_.get(4))))
print('now begin...')
while True:
ret_, frame_ = video_.read()
if not ret_: # or len(fps_list_) == 0:
print('end of video...')
break
result_frame = predictor.anime_image_only(frame_)
if frame_count_ % save_per_frames == 0:
out_video.write(result_frame)
frame_count_ = frame_count_ + 1
if frame_count_ % 100 == 0:
print("{}/{} processed...".format(frame_count_, int(total_frames)), flush=False)
6.最终视频
合成最终所需要的视频:
# 合并生成的视频和之前分离的音频:
!ffmpeg -i codes/videos/liyunlong/hayao_格式工厂混流 亮剑-03+亮剑-03+亮剑-04 00_00_23-.mp4 -i codes/videos/liyunlong/音频1.aac -c:v copy -c:a aac -strict experimental codes/videos/liyunlong/李云龙二次元化.mp4
这样就大功告成啦~~~
你可以在此基础上:
- 更换你喜欢的视频
- 更换其他paddle预训练好的模型
- 甚至可以尝试自己动手训练定制化的模型!
打滚卖萌求star、fork!
- 视频效果前往B站观看效果最佳:李云龙二次元风格化:
- github开源repo:李云龙二次元风格化
- 百度AIstudio开源地址,一键fork即可运行: 李云龙二次元风格化!一键fork你也能行
具体详细操作也在AIstudio上一步步列举了,求star求fork! - csdn步骤解析: 李云龙二次元风格化!一键fork你也能行
在PaddleGAN 的基础上做了些微小的改动,鸣谢.

 142 Dec 24, 2022
142 Dec 24, 2022
 203 Dec 30, 2022
203 Dec 30, 2022
 3 May 09, 2022
3 May 09, 2022
 418 Dec 29, 2022
418 Dec 29, 2022
 28 Jan 01, 2023
28 Jan 01, 2023
 50 Jan 05, 2023
50 Jan 05, 2023
 3 May 11, 2022
3 May 11, 2022
 202 Dec 13, 2022
202 Dec 13, 2022
 95 Dec 30, 2022
95 Dec 30, 2022
 7 Dec 22, 2022
7 Dec 22, 2022
 7 Oct 20, 2022
7 Oct 20, 2022
 10 Nov 09, 2022
10 Nov 09, 2022
 123 Jan 05, 2023
123 Jan 05, 2023
 24 Nov 02, 2022
24 Nov 02, 2022
 116 Dec 23, 2022
116 Dec 23, 2022
 3 Aug 08, 2021
3 Aug 08, 2021
 1 Feb 10, 2022
1 Feb 10, 2022
 3 Aug 05, 2022
3 Aug 05, 2022
 336 Dec 27, 2022
336 Dec 27, 2022
 209 Dec 30, 2022
209 Dec 30, 2022