Deep Unsupervised Image Hashing by Maximizing Bit Entropy
This is the PyTorch implementation of accepted AAAI 2021 paper: Deep Unsupervised Image Hashing by Maximizing Bit Entropy
Proposed Bi-half layer
| A simple, parameter-free, bi-half coding layer to maximize hash channel capacity | 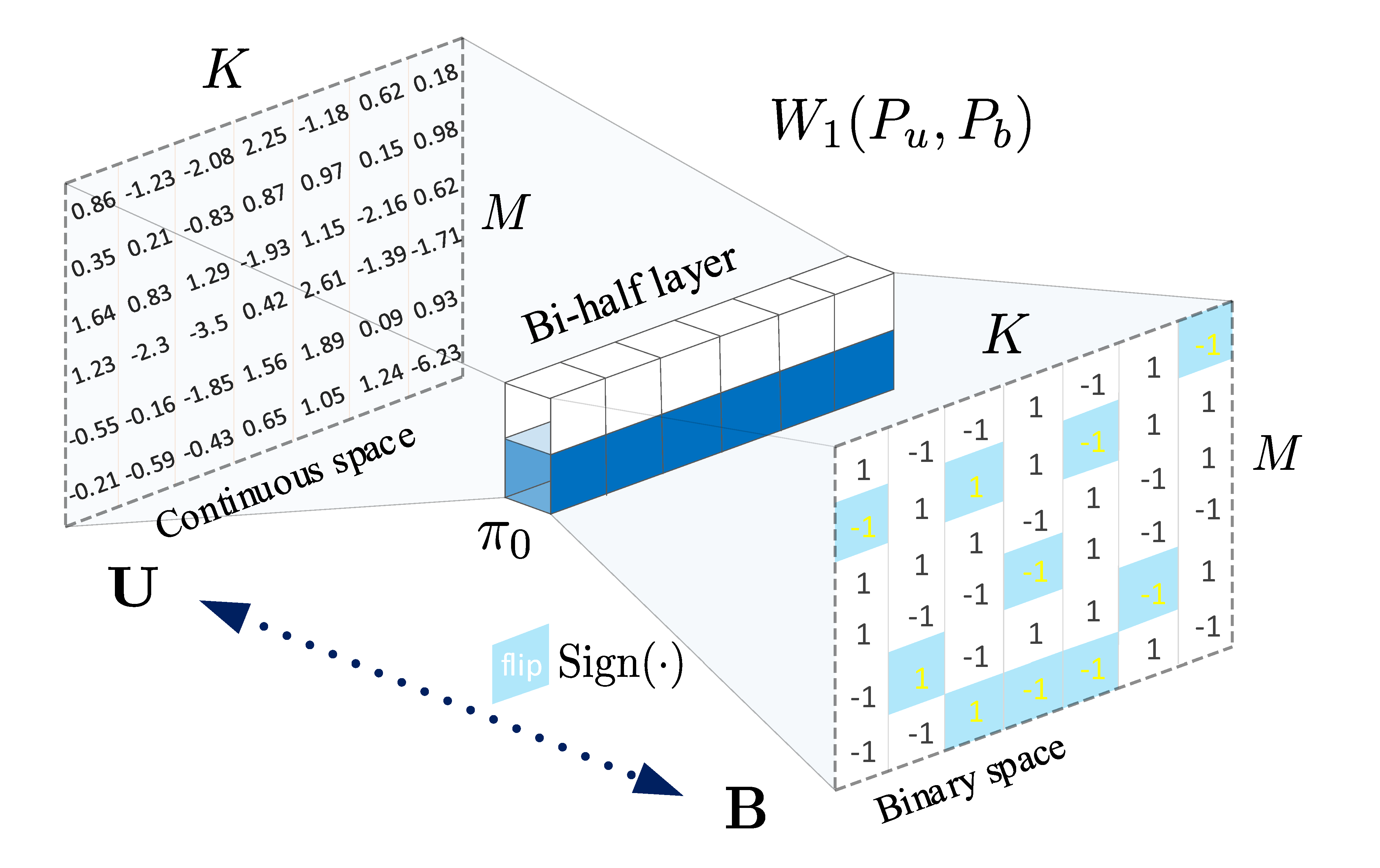 |
Datasets and Architectures on different settings
Experiments on 5 image datasets: Flickr25k, Nus-wide, Cifar-10, Mscoco, Mnist, and 2 video datasets: Ucf-101 and Hmdb-51. According to different settings, we divided them into: i) Train an AutoEncoder on Mnist; ii) Image Hashing on Flickr25k, Nus-wide, Cifar-10, Mscoco using Pre-trained Vgg; iii) Video Hashing on Ucf-101 and Hmdb-51 using Pre-trained 3D models.
Glance
3 settings ── AutoEncoder ── ── ── ── ImageHashing ── ── ── ── VideoHashing
├── Sign.py ├── Cifar10_I.py └── main.py
├── SignReg.py ├── Cifar10_II.py
└── BiHalf.py ├── Flickr25k.py
└── Mscoco.py
Datasets download
| # | Datasets | Download |
|---|---|---|
| 1 | Flick25k | Link |
| 2 | Mscoco | Link |
| 3 | Nuswide | Link |
| 4 | Cifar10 | Link |
| 5 | Mnist | Link |
| 6 | Ucf101 | Link |
| 7 | Hmdb51 | Link |
For video datasets, we converted them from avi to jpg files. The original avi videos can be download: Ucf101 and Hmdb51.
Implementation Details for Video Setup
For the video datasets ucf101 and hmdb51, to generate a training sample, we first select a video frame by uniform sampling, and then generate a 16-frame clip around the frame. If the selected position has less than 16 frames before the video ends, then we repeat the procedure until it fits. We spatially resize the cropped sample to 112 x 112 pixels, resulting in one training sample with size of 3 channels x 16 frames x 112 pixels x 112 pixels. In the retrieval, we adopt sliding window to generate clips as input, i.e, each video is split into non-overlapping 16-frame clips. Each video has an average 92 non-overlapped clips. Take the ucf101 for example, we obtain a query set of 3,783 videos containing 348,047 non-overlapped clips, and the retrieval set of 9,537 videos containing 891,961 clips. We then input the non-overlapped clips to extract binary descriptors for hashing. For more details, please see the paper.
Pretrained model
You can download kinetics pre-trained 3D models: ResNet-34 and ResNet-101 here.
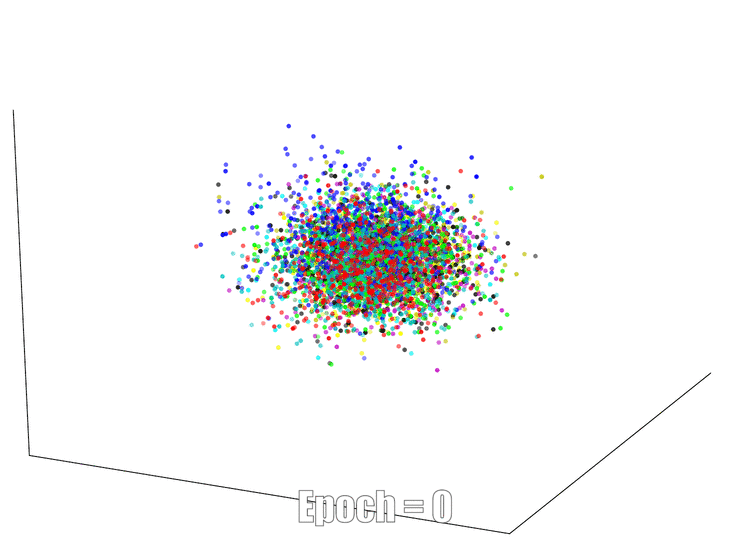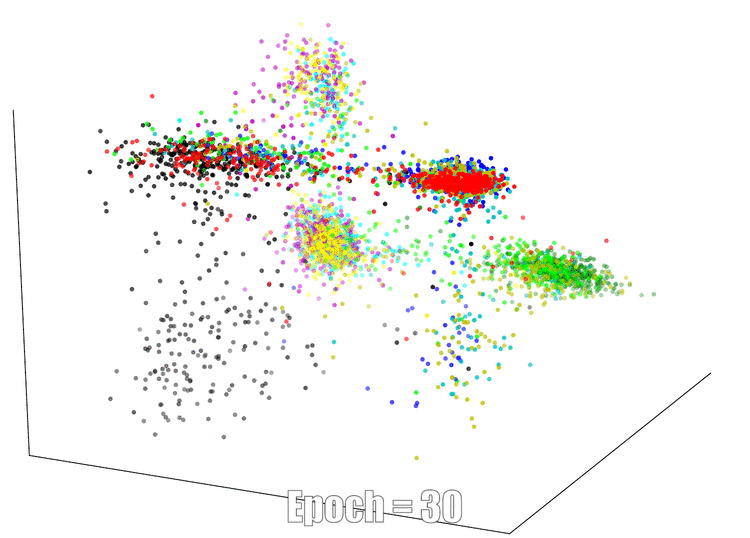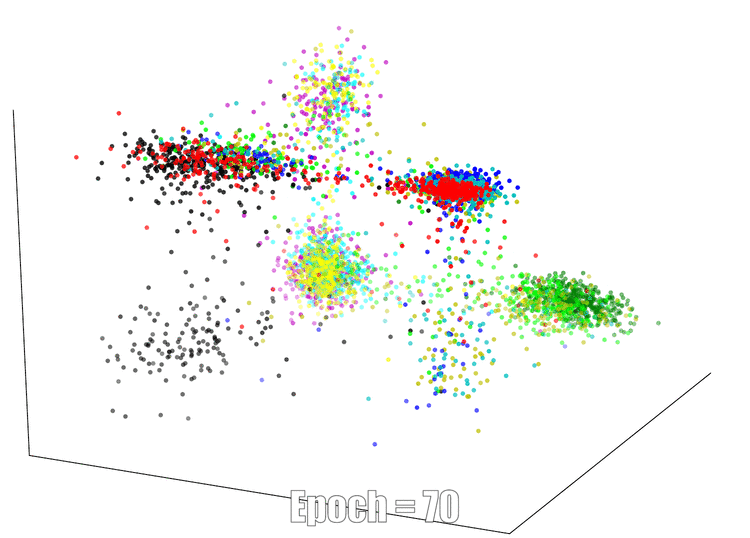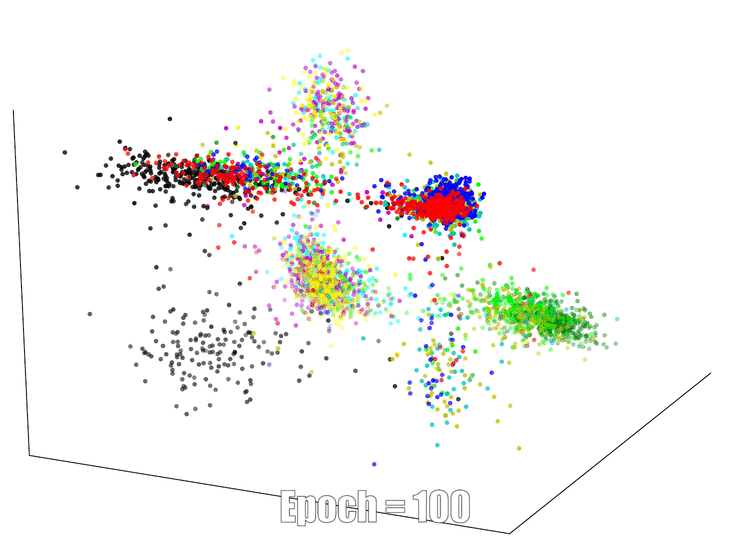
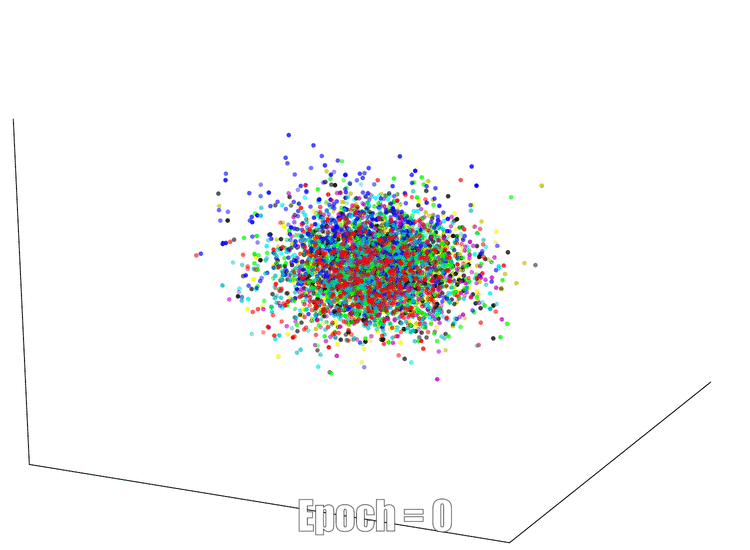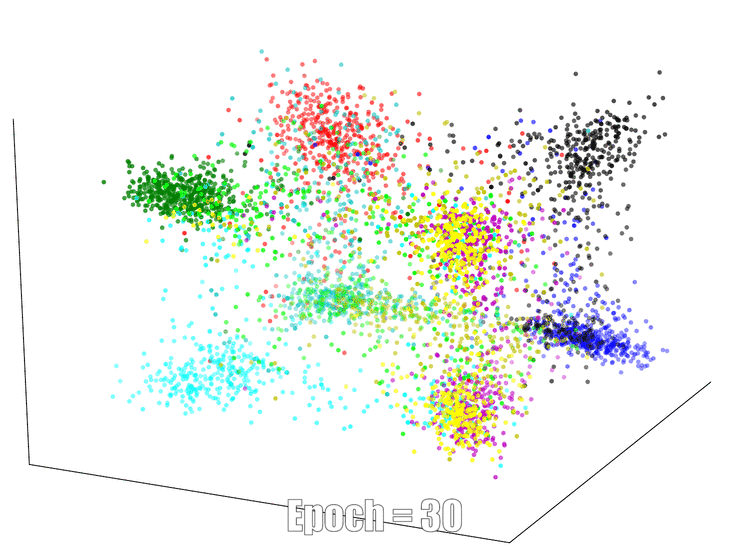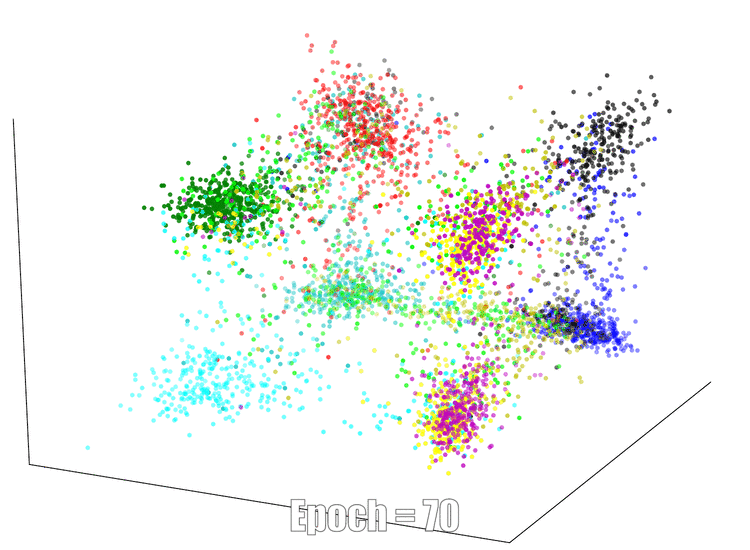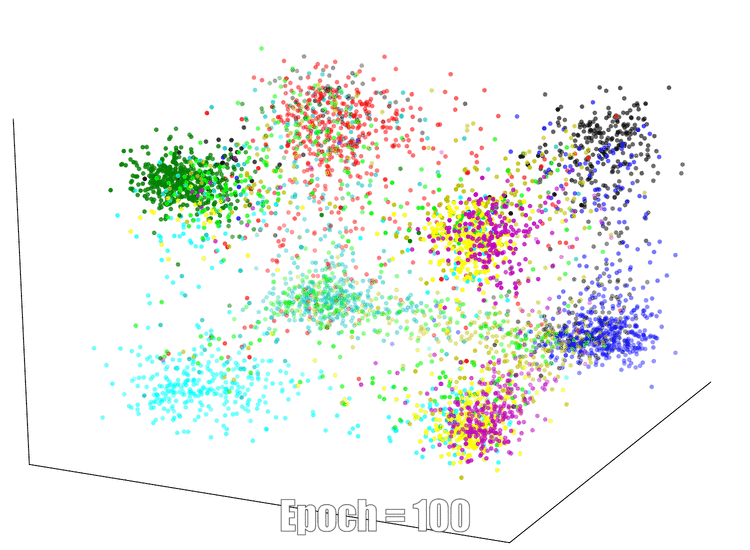
3D Visualization
The continuous feature visualization on an AutoEncoder using Mnist. We compare 3 different models: sign layer, sign+reg and our bi-half layer.
| Sign Layer | Sign + Reg | Bi-half Layer |
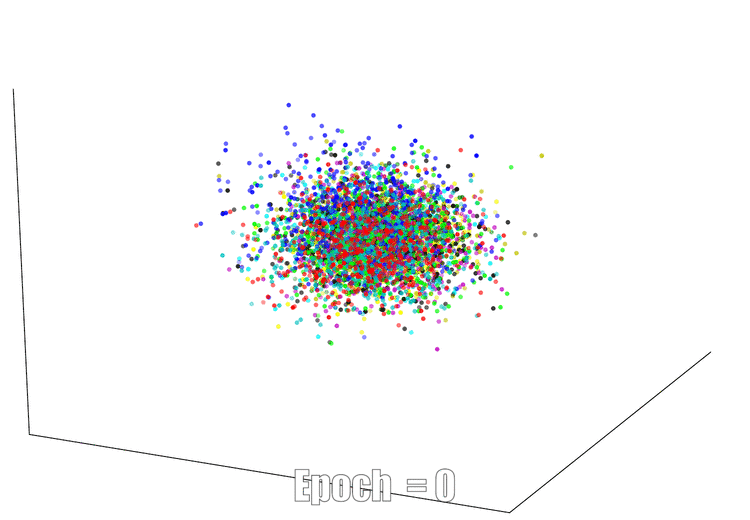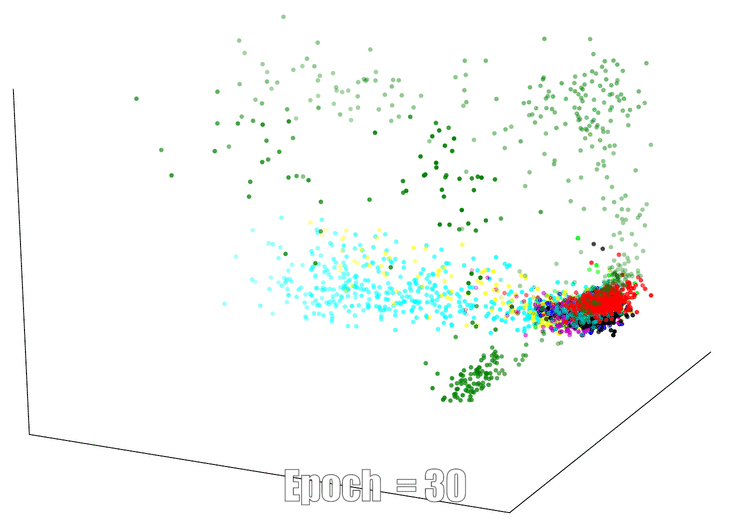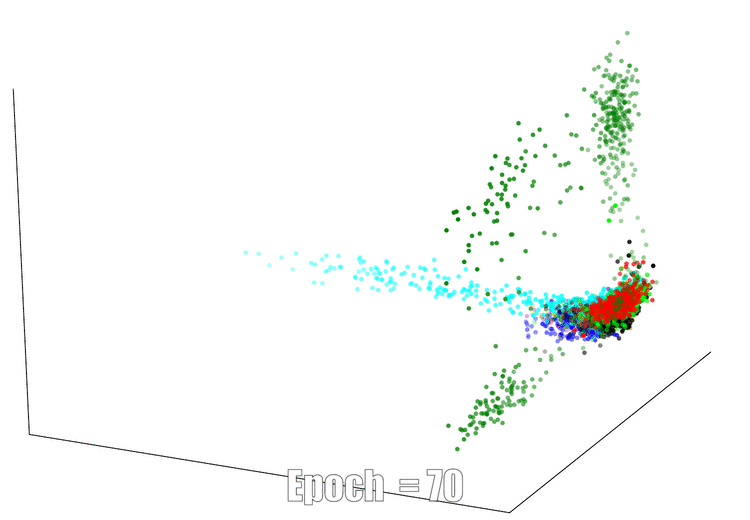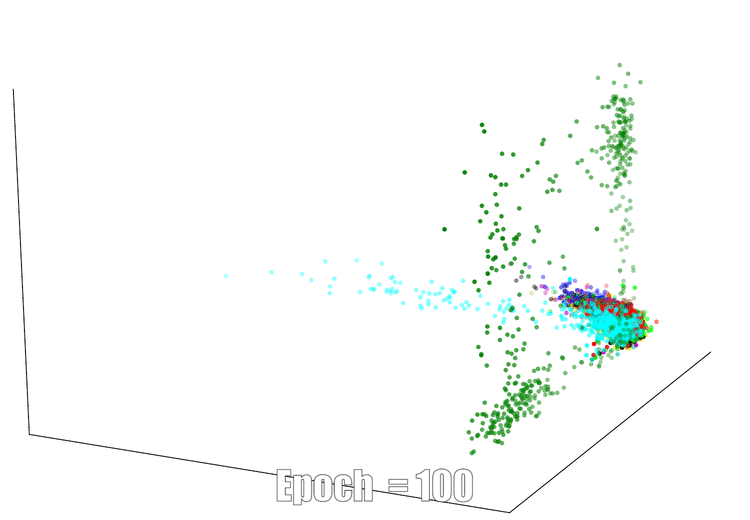 |
 |
 |
Citation
If you find the code in this repository useful for your research consider citing it.
@article{liAAAI2021,
title={Deep Unsupervised Image Hashing by Maximizing Bit Entropy},
author={Li, Yunqiang and van Gemert, Jan},
journal={AAAI},
year={2021}
}
Contact
If you have any problem about our code, feel free to contact

 111 Dec 31, 2022
111 Dec 31, 2022
 24 Nov 11, 2022
24 Nov 11, 2022
 38 Dec 16, 2022
38 Dec 16, 2022
 12 May 12, 2022
12 May 12, 2022
 26 Oct 06, 2022
26 Oct 06, 2022
 112 Jan 05, 2023
112 Jan 05, 2023
 54 Nov 28, 2022
54 Nov 28, 2022
 88 Dec 01, 2022
88 Dec 01, 2022
 65 Dec 10, 2022
65 Dec 10, 2022
 44 Dec 27, 2022
44 Dec 27, 2022
 260 Jan 03, 2023
260 Jan 03, 2023
 52 Jan 07, 2023
52 Jan 07, 2023
 168 Dec 24, 2022
168 Dec 24, 2022
 261 Jan 09, 2023
261 Jan 09, 2023
 160 Sep 20, 2022
160 Sep 20, 2022
 17 Nov 08, 2022
17 Nov 08, 2022
 1 Jan 13, 2022
1 Jan 13, 2022
 20 Sep 04, 2022
20 Sep 04, 2022
 5.2k Jan 02, 2023
5.2k Jan 02, 2023
 93 Dec 28, 2022
93 Dec 28, 2022