Torchsort
![]()
Fast, differentiable sorting and ranking in PyTorch.
Pure PyTorch implementation of Fast Differentiable Sorting and Ranking (Blondel et al.). Much of the code is copied from the original Numpy implementation at google-research/fast-soft-sort, with the isotonic regression solver rewritten as a PyTorch C++ and CUDA extension.
Install
pip install torchsort
To build the CUDA extension you will need the CUDA toolchain installed. If you want to build in an environment without a CUDA runtime (e.g. docker), you will need to export the environment variable TORCH_CUDA_ARCH_LIST="Pascal;Volta;Turing;Ampere" before installing.
Usage
torchsort exposes two functions: soft_rank and soft_sort, each with parameters regularization ("l2" or "kl") and regularization_strength (a scalar value). Each will rank/sort the last dimension of a 2-d tensor, with an accuracy dependant upon the regularization strength:
import torch
import torchsort
x = torch.tensor([[8, 0, 5, 3, 2, 1, 6, 7, 9]])
torchsort.soft_sort(x, regularization_strength=1.0)
# tensor([[0.5556, 1.5556, 2.5556, 3.5556, 4.5556, 5.5556, 6.5556, 7.5556, 8.5556]])
torchsort.soft_sort(x, regularization_strength=0.1)
# tensor([[-0., 1., 2., 3., 5., 6., 7., 8., 9.]])
torchsort.soft_rank(x)
# tensor([[8., 1., 5., 4., 3., 2., 6., 7., 9.]])
Both operations are fully differentiable, on CPU or GPU:
x = torch.tensor([[8., 0., 5., 3., 2., 1., 6., 7., 9.]], requires_grad=True).cuda()
y = torchsort.soft_sort(x)
torch.autograd.grad(y[0, 0], x)
# (tensor([[0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111]],
# device='cuda:0'),)
Example
Spearman's Rank Coefficient
Spearman's rank coefficient is a very useful metric for measuring how monotonically related two variables are. We can use Torchsort to create a differentiable Spearman's rank coefficient function so that we can optimize a model directly for this metric:
import torch
import torchsort
def spearmanr(pred, target, **kw):
pred = torchsort.soft_rank(pred, **kw)
target = torchsort.soft_rank(target, **kw)
pred = pred - pred.mean()
pred = pred / pred.norm()
target = target - target.mean()
target = target / target.norm()
return (pred * target).sum()
pred = torch.tensor([[1., 2., 3., 4., 5.]], requires_grad=True)
target = torch.tensor([[5., 6., 7., 8., 7.]])
spearman = spearmanr(pred, target)
# tensor(0.8321)
torch.autograd.grad(spearman, pred)
# (tensor([[-5.5470e-02, 2.9802e-09, 5.5470e-02, 1.1094e-01, -1.1094e-01]]),)
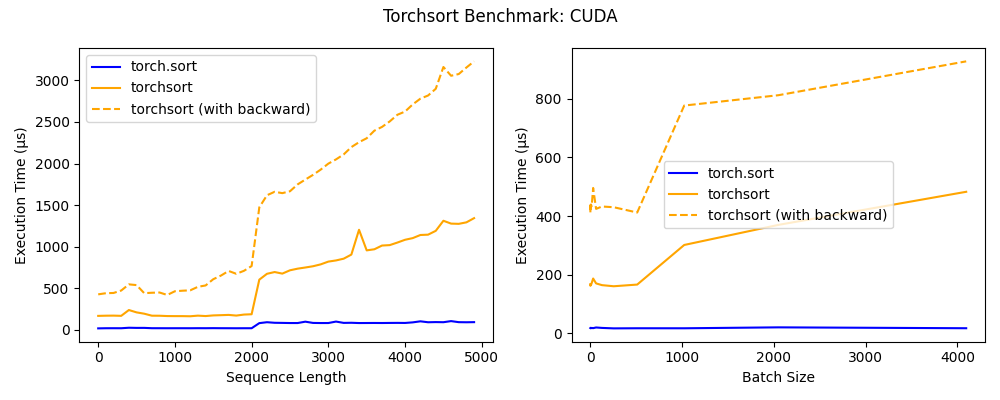
Benchmark

torchsort and fast_soft_sort each operate with a time complexity of O(n log n), each with some additional overhead when compared to the built-in torch.sort. With a batch size of 1 (see left), the Numba JIT'd forward pass of fast_soft_sort performs about on-par with the torchsort CPU kernel, however its backward pass still relies on some Python code, which greatly penalizes its performance.
Furthermore, the torchsort kernel supports batches, and yields much better performance than fast_soft_sort as the batch size increases.

The torchsort CUDA kernel performs quite well with sequence lengths under ~2000, and scales to extremely large batch sizes. In the future the CUDA kernel can likely be further optimized to achieve performance closer to that of the built in torch.sort.
Reference
@inproceedings{blondel2020fast,
title={Fast differentiable sorting and ranking},
author={Blondel, Mathieu and Teboul, Olivier and Berthet, Quentin and Djolonga, Josip},
booktitle={International Conference on Machine Learning},
pages={950--959},
year={2020},
organization={PMLR}
}
















 22 May 28, 2022
22 May 28, 2022
 9 Aug 13, 2022
9 Aug 13, 2022
 204 Jan 08, 2023
204 Jan 08, 2023
 8 May 11, 2022
8 May 11, 2022
 16 Dec 27, 2022
16 Dec 27, 2022
 8 Aug 18, 2022
8 Aug 18, 2022
 200 Nov 17, 2022
200 Nov 17, 2022
 17 Nov 17, 2022
17 Nov 17, 2022
 113 Jan 06, 2023
113 Jan 06, 2023
 156 Dec 28, 2022
156 Dec 28, 2022
 26 Dec 28, 2022
26 Dec 28, 2022
 38 Nov 08, 2022
38 Nov 08, 2022
 3 Feb 21, 2022
3 Feb 21, 2022
 26 Nov 14, 2022
26 Nov 14, 2022
 236 Dec 22, 2022
236 Dec 22, 2022
 180 Jan 05, 2023
180 Jan 05, 2023
 25 Dec 28, 2022
25 Dec 28, 2022
 28 Nov 29, 2022
28 Nov 29, 2022
 21 Dec 14, 2022
21 Dec 14, 2022
 274 Dec 26, 2022
274 Dec 26, 2022