Music Comments Dataset
A music comments dataset, containing 39,051 comments for 27,384 songs.
For academic research use only.
Introduction
This dataset is part of a recent multimodal deep learning project on music and natural language that I have been working on. The complete dataset contains 30s of audio, metadata, lyrics, and comments for each piece of data. This dataset contains only the lyrics and comments sections.
In the current stage, it only contains 39,051 comments for 27,384 songs (for dataset_summarization_positive.pkl) and can be larger if necessary (for other files).
Because the audio data is much less than the review data, I kept only this part as the dataset in order to ensure that music and reviews appear in pairs.
Here is a data sample:
Lyrics: Come up to meet you, tell you I'm sorry; You don't know how lovely you are; I had to find you, tell you I need you; ; Tell you I set you apart; Tell me your secrets and ask me your questions; Oh, let's go back to the start; ; Running in circles, coming up tails; Heads on a science apart; Nobody said it was easy; ; It's such a shame for us to part; Nobody said it was easy; No one ever said it would be this hard; ; Oh, take me back to the start; I was just guessing at numbers and figures; Pulling the puzzles apart; Questions of science, science and progress; ; Do not speak as loud as my heart; ; But tell me you love me, come back and haunt me; Oh and I rush to the start; Running in circles, chasing our tails; ; Coming back as we are; Nobody said it was easy; Oh, it's such a shame for us to part; Nobody said it was easy; No one ever said it would be so hard; I'm going back to the start; Oh ooh, ooh ooh ooh ooh; Ah ooh, ooh ooh ooh ooh; Oh ooh, ooh ooh ooh ooh; Oh ooh, ooh ooh ooh ooh
Ground Truth: The song is like poetry with many meanings to be sifted out applicable to many people in many different relationship situations. I find the lyrics touch me as if specifically written regarding my own situations at times. The following meaning I describe in no way reflects any situation I have ever had to face.
Data Source and Data Preprocessing
The audio and metadata files are from the Music4All Dataset, which I cannot make available directly due to agreeement restrictions, so anyone who would like to request that dataset can contact the authors directly.
The review data is mainly from songmeanings.com. I have done some data pre-processing to make the comment data more concise.
The first is the summarization method. I use the generative summarisation method to remove useless information from the comments (See Figure 1).
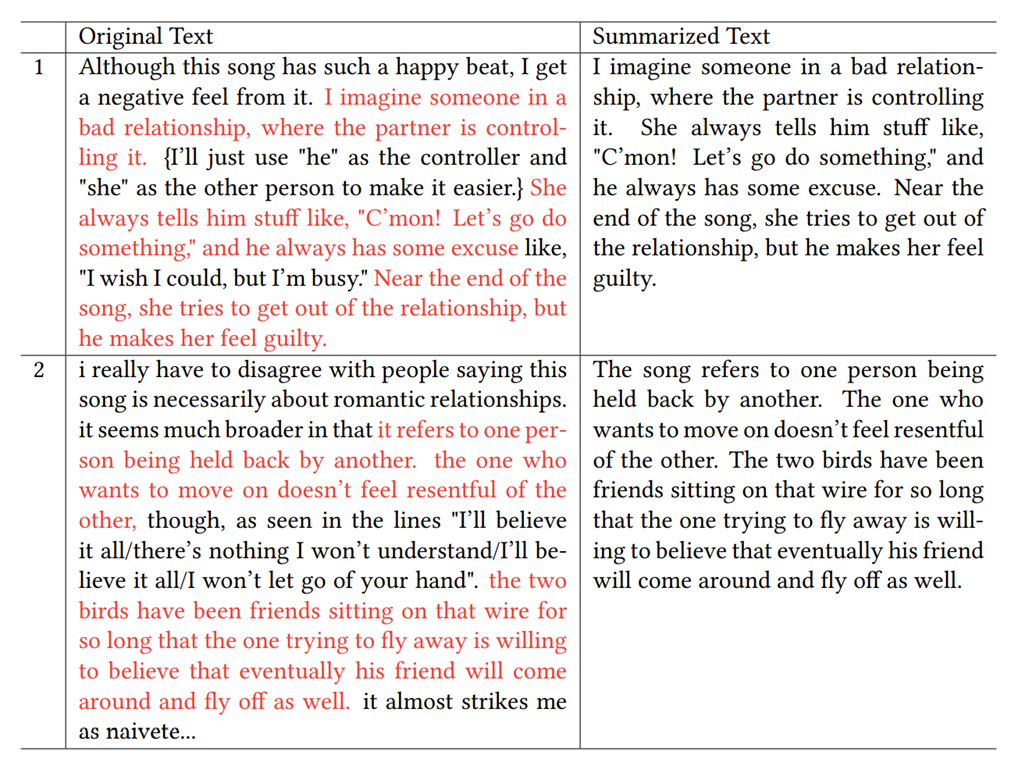
The second is the positive method. Each original comment carries a rating, which relates to the degree to which the comment itself is agreed by the community. The summarization token means that I only pick comments which have ratings > 0. The not_negative tokens means that the comments have ratings >= 0.
Folder Structure
.
├── README.md
├── codes
│ └── data.py
└── dataset
├── dataset_summarization_positive.pkl
├── dataset_summarization_not_negative.pkl
├── dataset_summarization.pkl
├── dataset_positive.pkl
├── dataset_not_negative.pkl
└── dataset.pkl
In the data.py file, I have provided a PyTorch Dataset class to use.
Data Format
the .pkl file is an object List. It can be loaded and read using LyricsCommentsDatasetPsuedo class in data.py.
Each data contains two attributes: lyrics and comment. A lyric may correspond to more than one comment, so I broadcast the lyrics to ensure that each comment has a corresponding lyric.
Citation
@article{zhanggenerating,
title={Generating Comments from Music and Lyrics},
author={Zhang, Yixiao and Dixon, Simon},
year={2021}
}

 23 Sep 22, 2022
23 Sep 22, 2022
 213 Jan 01, 2023
213 Jan 01, 2023
 3.8k Dec 26, 2022
3.8k Dec 26, 2022
 1.5k Dec 26, 2022
1.5k Dec 26, 2022
 7 Nov 24, 2022
7 Nov 24, 2022
 148 Dec 26, 2022
148 Dec 26, 2022
 2.2k Jan 09, 2023
2.2k Jan 09, 2023
 1 Feb 07, 2022
1 Feb 07, 2022
 2.3k Jan 05, 2023
2.3k Jan 05, 2023
 94 Dec 27, 2022
94 Dec 27, 2022
 6 Oct 07, 2021
6 Oct 07, 2021
 223 Jan 02, 2023
223 Jan 02, 2023
 3.2k Dec 28, 2022
3.2k Dec 28, 2022
 231 Nov 18, 2022
231 Nov 18, 2022
 1 Dec 06, 2021
1 Dec 06, 2021
 58 Dec 20, 2022
58 Dec 20, 2022
 27 Dec 22, 2022
27 Dec 22, 2022
 106 Nov 28, 2022
106 Nov 28, 2022
 33 Sep 22, 2022
33 Sep 22, 2022
 2 Oct 17, 2021
2 Oct 17, 2021