Netflix-recommendation-system
NLP, Machine learning

About
Recommendation algorithms are at the core of the Netflix product. It provides their members with personalized suggestions to reduce the amount of time and frustration to find something great content to watch. Because of the importance of our recommendations, they continually seek to improve them by advancing the state-of-the-art in the field. They do this by using the data about what content our members watch and enjoy along with how they interact with our service to get better at figuring out what the next great movie or TV show for them will be.
Types
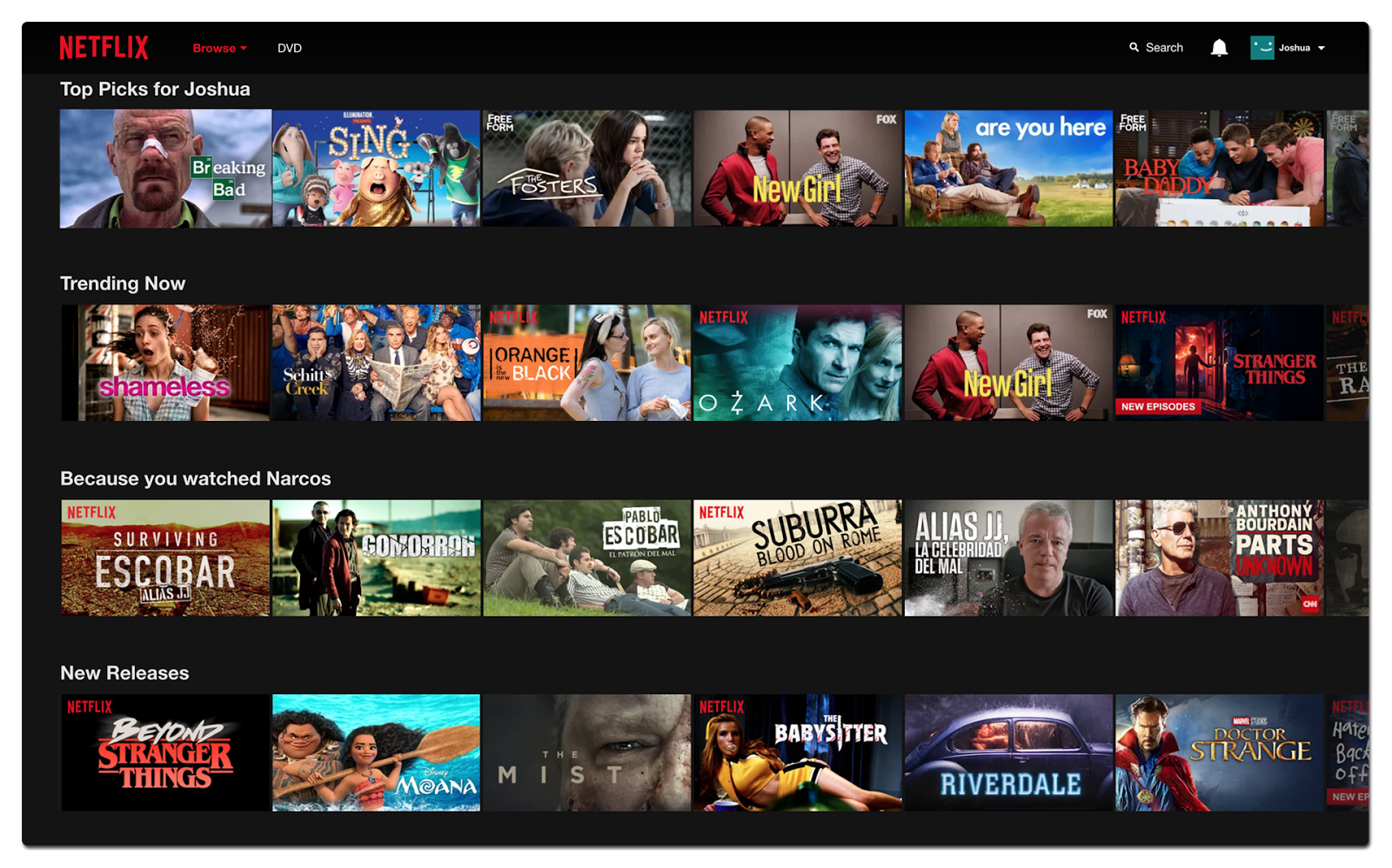
The categories under "Trending Now" and "New Releases" are Non-Personalized Recommendation System
The categories under "Because you watched" are Personalized Recommendation System
NLP
Natural language processing is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data.

#1 Tokenization
Tokenization is the process of breaking down sentence or paragraphs into smaller chunks of words called tokens.
#2 Stop Words Removal
On removal of some words, the meaning of the sentence doesn't change, like and, am. Those words are called stop-words and should be removed before feeding to any algorithm. In datasets, some non-stop words repeat very frequently. Those words too should be removed to get an unbiased result from the algorithm.
#3 Vectorization
After tokenization, and stop words removal, our "content" are still in string format. We need to convert those strings to numbers based on their importance (features). We use TF-IDF vectorization to convert those text to vector of importance. With TF-IDF we can extract important words in our data. It assign rarely occurring words a high number, and frequently occurring words a very low number.

 179 Jan 07, 2023
179 Jan 07, 2023
 440 Dec 18, 2022
440 Dec 18, 2022
 28 Oct 30, 2022
28 Oct 30, 2022
 5 Dec 28, 2021
5 Dec 28, 2021
 46 Dec 05, 2022
46 Dec 05, 2022
 2 Oct 20, 2021
2 Oct 20, 2021
 11 Nov 16, 2022
11 Nov 16, 2022
 483 Jan 02, 2023
483 Jan 02, 2023
 114 Nov 04, 2022
114 Nov 04, 2022
 847 Dec 19, 2022
847 Dec 19, 2022
 1 Nov 11, 2021
1 Nov 11, 2021
 3 Oct 14, 2022
3 Oct 14, 2022
 121 Jan 01, 2023
121 Jan 01, 2023
 2 Jan 17, 2022
2 Jan 17, 2022
 3 Jan 27, 2022
3 Jan 27, 2022
 606 Dec 28, 2022
606 Dec 28, 2022
 273 Dec 17, 2022
273 Dec 17, 2022
 37 Nov 29, 2022
37 Nov 29, 2022
 31 Oct 30, 2022
31 Oct 30, 2022
 10 Jul 01, 2022
10 Jul 01, 2022