Attention-OCR
Authours: Qi Guo and Yuntian Deng
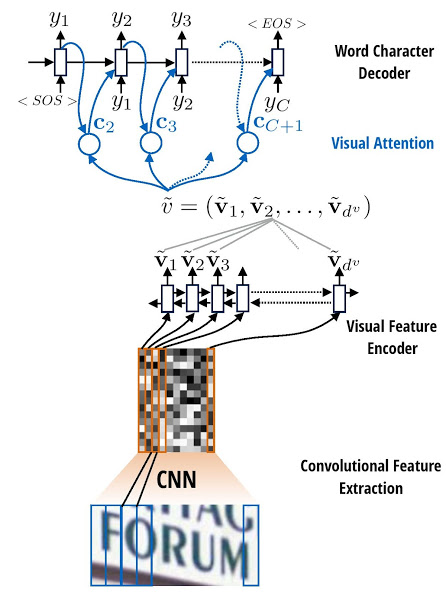
Visual Attention based OCR. The model first runs a sliding CNN on the image (images are resized to height 32 while preserving aspect ratio). Then an LSTM is stacked on top of the CNN. Finally, an attention model is used as a decoder for producing the final outputs.
Prerequsites
Most of our code is written based on Tensorflow, but we also use Keras for the convolution part of our model. Besides, we use python package distance to calculate edit distance for evaluation. (However, that is not mandatory, if distance is not installed, we will do exact match).
Tensorflow: Installation Instructions (tested on 0.12.1)
Distance (Optional):
wget http://www.cs.cmu.edu/~yuntiand/Distance-0.1.3.tar.gz
tar zxf Distance-0.1.3.tar.gz
cd distance; sudo python setup.py install
Usage:
Note: We assume that the working directory is Attention-OCR.
Train
Data Preparation
We need a file (specified by parameter data-path) containing the path of images and the corresponding characters, e.g.:
path/to/image1 abc
path/to/image2 def
And we also need to specify a data-base-dir parameter such that we read the images from path data-base-dir/path/to/image. If data-path contains absolute path of images, then data-base-dir needs to be set to /.
A Toy Example
For a toy example, we have prepared a training dataset of the specified format, which is a subset of Synth 90k
wget http://www.cs.cmu.edu/~yuntiand/sample.tgz
tar zxf sample.tgz
python src/launcher.py --phase=train --data-path=sample/sample.txt --data-base-dir=sample --log-path=log.txt --no-load-model
After a while, you will see something like the following output in log.txt:
...
2016-06-08 20:47:22,335 root INFO Created model with fresh parameters.
2016-06-08 20:47:52,852 root INFO current_step: 0
2016-06-08 20:48:01,253 root INFO step_time: 8.400597, step perplexity: 38.998714
2016-06-08 20:48:01,385 root INFO current_step: 1
2016-06-08 20:48:07,166 root INFO step_time: 5.781749, step perplexity: 38.998445
2016-06-08 20:48:07,337 root INFO current_step: 2
2016-06-08 20:48:12,322 root INFO step_time: 4.984972, step perplexity: 39.006730
2016-06-08 20:48:12,347 root INFO current_step: 3
2016-06-08 20:48:16,821 root INFO step_time: 4.473902, step perplexity: 39.000267
2016-06-08 20:48:16,859 root INFO current_step: 4
2016-06-08 20:48:21,452 root INFO step_time: 4.593249, step perplexity: 39.009864
2016-06-08 20:48:21,530 root INFO current_step: 5
2016-06-08 20:48:25,878 root INFO step_time: 4.348195, step perplexity: 38.987707
2016-06-08 20:48:26,016 root INFO current_step: 6
2016-06-08 20:48:30,851 root INFO step_time: 4.835423, step perplexity: 39.022887
Note that it takes quite a long time to reach convergence, since we are training the CNN and attention model simultaneously.
Test and visualize attention results
The test data format shall be the same as training data format. We have also prepared a test dataset of the specified format, which includes ICDAR03, ICDAR13, IIIT5k and SVT.
wget http://www.cs.cmu.edu/~yuntiand/evaluation_data.tgz
tar zxf evaluation_data.tgz
We also provide a trained model on Synth 90K:
wget http://www.cs.cmu.edu/~yuntiand/model.tgz
tar zxf model.tgz
python src/launcher.py --phase=test --visualize --data-path=evaluation_data/svt/test.txt --data-base-dir=evaluation_data/svt --log-path=log.txt --load-model --model-dir=model --output-dir=results
After a while, you will see something like the following output in log.txt:
2016-06-08 22:36:31,638 root INFO Reading model parameters from model/translate.ckpt-47200
2016-06-08 22:36:40,529 root INFO Compare word based on edit distance.
2016-06-08 22:36:41,652 root INFO step_time: 1.119277, step perplexity: 1.056626
2016-06-08 22:36:41,660 root INFO 1.000000 out of 1 correct
2016-06-08 22:36:42,358 root INFO step_time: 0.696687, step perplexity: 2.003350
2016-06-08 22:36:42,363 root INFO 1.666667 out of 2 correct
2016-06-08 22:36:42,831 root INFO step_time: 0.466550, step perplexity: 1.501963
2016-06-08 22:36:42,835 root INFO 2.466667 out of 3 correct
2016-06-08 22:36:43,402 root INFO step_time: 0.562091, step perplexity: 1.269991
2016-06-08 22:36:43,418 root INFO 3.366667 out of 4 correct
2016-06-08 22:36:43,897 root INFO step_time: 0.477545, step perplexity: 1.072437
2016-06-08 22:36:43,905 root INFO 4.366667 out of 5 correct
2016-06-08 22:36:44,107 root INFO step_time: 0.195361, step perplexity: 2.071796
2016-06-08 22:36:44,127 root INFO 5.144444 out of 6 correct
Example output images in results/correct (the output directory is set via parameter output-dir and the default is results): (Look closer to see it clearly.)
Format: Image index (predicted/ground truth) Image file
Image 0 (j/j):

Image 1 (u/u):

Image 2 (n/n):

Image 3 (g/g):

Image 4 (l/l):

Image 5 (e/e):

Parameters:
-
Control
phase: Determine whether to train or test.visualize: Valid ifphaseis set to test. Output the attention maps on the original image.load-model: Load model frommodel-diror not.
-
Input and output
data-base-dir: The base directory of the image path indata-path. If the image path indata-pathis absolute path, set it to/.data-path: The path containing data file names and labels. Format per line:image_path characters.model-dir: The directory for saving and loading model parameters (structure is not stored).log-path: The path to put log.output-dir: The path to put visualization results ifvisualizeis set to True.steps-per-checkpoint: Checkpointing (print perplexity, save model) per how many steps
-
Optimization
num-epoch: The number of whole data passes.batch-size: Batch size. Only valid ifphaseis set to train.initial-learning-rate: Initial learning rate, note the we use AdaDelta, so the initial value doe not matter much.
-
Network
target-embedding-size: Embedding dimension for each target.attn-use-lstm: Whether or not use LSTM attention decoder cell.attn-num-hidden: Number of hidden units in attention decoder cell.attn-num-layers: Number of layers in attention decoder cell. (Encoder number of hidden units will beattn-num-hidden*attn-num-layers).target-vocab-size: Target vocabulary size. Default is = 26+10+3 # 0: PADDING, 1: GO, 2: EOS, >2: 0-9, a-z
References
Convert a formula to its LaTex source

 6 Dec 09, 2022
6 Dec 09, 2022
 152 Dec 20, 2022
152 Dec 20, 2022
 32 Jul 24, 2022
32 Jul 24, 2022
 10 Sep 23, 2022
10 Sep 23, 2022
 5 Oct 20, 2022
5 Oct 20, 2022
 62 Oct 10, 2022
62 Oct 10, 2022
 1 Feb 12, 2022
1 Feb 12, 2022
 0 Nov 29, 2021
0 Nov 29, 2021
 261 Jan 02, 2023
261 Jan 02, 2023
 1 Jan 27, 2022
1 Jan 27, 2022
 70 Jun 30, 2022
70 Jun 30, 2022
 218 Dec 31, 2022
218 Dec 31, 2022
 4 Mar 10, 2022
4 Mar 10, 2022
 8 Dec 20, 2022
8 Dec 20, 2022
 167 Nov 20, 2022
167 Nov 20, 2022
 350 Dec 19, 2022
350 Dec 19, 2022
 422 Jan 03, 2023
422 Jan 03, 2023
 1 Nov 07, 2021
1 Nov 07, 2021
 10 Dec 04, 2022
10 Dec 04, 2022
 948 Dec 23, 2022
948 Dec 23, 2022