Near-Duplicate Video Retrieval
with Deep Metric Learning
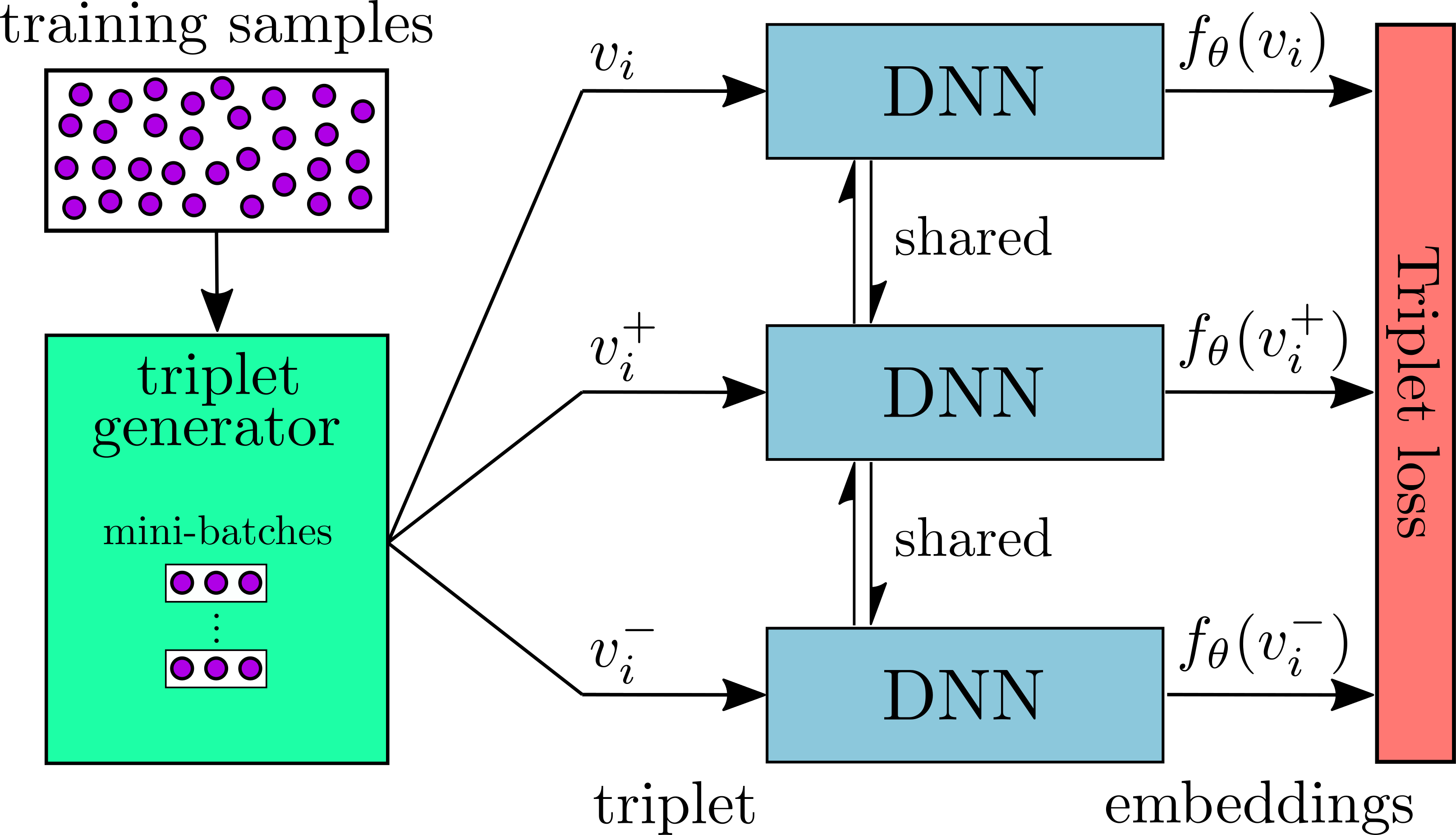
This repository contains the Tensorflow implementation of the paper Near-Duplicate Video Retrieval with Deep Metric Learning. It provides code for training and evalutation of a Deep Metric Learning (DML) network on the problem of Near-Duplicate Video Retrieval (NDVR). During training, the DML network is fed with video triplets, generated by a triplet generator. The network is trained based on the triplet loss function. The architecture of the network is displayed in the figure below. For evaluation, mean Average Precision (mAP) and Presicion-Recall curve (PR-curve) are calculated. Two publicly available dataset are supported, namely VCDB and CC_WEB_VIDEO.
Prerequisites
- Python
- Tensorflow 1.xx
Getting started
Installation
- Clone this repo:
git clone https://github.com/MKLab-ITI/ndvr-dml
cd ndvr-dml
- You can install all the dependencies by
pip install -r requirements.txt
or
conda install --file requirements.txt
Triplet generation
Run the triplet generation process for each dataset, VCDB and CC_WEB_VIDEO. This process will generate two files for each dataset:
- the global feature vectors for each video in the dataset:
<output_dir>/<dataset>_features.npy - the generated triplets:
<output_dir>/<dataset>_triplets.npy
To execute the triplet generation process, do as follows:
-
The code does not extract features from videos. Instead, the .npy files of the already extracted features have to be provided. You may use the tool in here to do so.
-
Create a file that contains the video id and the path of the feature file for each video in the processing dataset. Each line of the file have to contain the video id (basename of the video file) and the full path to the corresponding .npy file of its features, separated by a tab character (\t). Example:
23254771545e5d278548ba02d25d32add952b2a4 features/23254771545e5d278548ba02d25d32add952b2a4.npy 468410600142c136d707b4cbc3ff0703c112575d features/468410600142c136d707b4cbc3ff0703c112575d.npy 67f1feff7f624cf0b9ac2ebaf49f547a922b4971 features/67f1feff7f624cf0b9ac2ebaf49f547a922b4971.npy ... -
Run the triplet generator and provide the generated file from the previous step, the name of the processed dataset, and the output directory.
python triplet_generator.py --dataset vcdb --feature_files vcdb_feature_files.txt --output_dir output_data/
- The global video features extracted based on the Intermediate CNN Features, and their generated triplets for both datasets can be found here.
DML training
- Train the DML network by providing the global features and triplet of VCDB, and a directory to save the trained model.
python train_dml.py --train_set output_data/vcdb_features.npy --triplets output_data/vcdb_triplets.npy --model_path model/
- Triplets from the CC_WEB_VIDEO can be injected if the global features and triplet of the evaluation set are provide.
python train_dml.py --evaluation_set output_data/cc_web_video_features.npy --evaluation_triplets output_data/cc_web_video_triplets.npy --train_set output_data/vcdb_features.npy --triplets output_data/vcdb_triplets.npy --model_path model/
Evaluation
- Evaluate the performance of the system by providing the trained model path and the global features of the CC_WEB_VIDEO.
python evaluation.py --fusion Early --evaluation_set output_data/cc_vgg_features.npy --model_path model/
OR
python evaluation.py --fusion Late --evaluation_features cc_web_video_feature_files.txt --evaluation_set output_data/cc_vgg_features.npy --model_path model/
- The mAP and PR-curve are returned
Citation
If you use this code for your research, please cite our paper.
@inproceedings{kordopatis2017dml,
title={Near-Duplicate Video Retrieval with Deep Metric Learning},
author={Kordopatis-Zilos, Giorgos and Papadopoulos, Symeon and Patras, Ioannis and Kompatsiaris, Yiannis},
booktitle={2017 IEEE International Conference on Computer Vision Workshop (ICCVW)},
year={2017},
}
Related Projects
ViSiL Intermediate-CNN-Features FIVR-200K
License
This project is licensed under the Apache License 2.0 - see the LICENSE file for details
Contact for further details about the project
Giorgos Kordopatis-Zilos ([email protected])
Symeon Papadopoulos ([email protected])

 65 Dec 09, 2022
65 Dec 09, 2022
 1 Dec 08, 2022
1 Dec 08, 2022
 3.2k Jan 08, 2023
3.2k Jan 08, 2023
 14 Nov 14, 2022
14 Nov 14, 2022
 0 Jul 01, 2021
0 Jul 01, 2021
 2 Aug 22, 2022
2 Aug 22, 2022
 87 Dec 24, 2022
87 Dec 24, 2022
 35 Dec 22, 2022
35 Dec 22, 2022
 1 Jan 26, 2022
1 Jan 26, 2022
 94 Nov 22, 2022
94 Nov 22, 2022
 131 Dec 16, 2022
131 Dec 16, 2022
 2 Jan 29, 2022
2 Jan 29, 2022
 82 Dec 29, 2022
82 Dec 29, 2022
 162 Dec 09, 2022
162 Dec 09, 2022
 77 Dec 22, 2022
77 Dec 22, 2022
 316 Dec 01, 2022
316 Dec 01, 2022
 28 Oct 20, 2022
28 Oct 20, 2022
 250 Dec 30, 2022
250 Dec 30, 2022
 57 Dec 15, 2022
57 Dec 15, 2022
 235 Jan 07, 2023
235 Jan 07, 2023